Hi all, I’ve been recently playing with some KPIs and different metrics and there is something that caught my attention: One of the KPIs is using unique count and the other one a normal count and I was expecting to see the same value in both since I’m 100% I don’t have any duplicates. Is this correct?
Hi Brian, a little late reply. It has been a busy week.
In Elasticsearch, the count of distinct values is approximate, it uses the HyperLogLog++ algorithm. Here is a reference to their documentation.
However, there is a precision_threshold setting that Elasticsearch provides. See this. You could set your precision_threshold in ChartFactor using custom metadata. In Studio, open the Metadata window and add the precision_threshold setting as shown below:
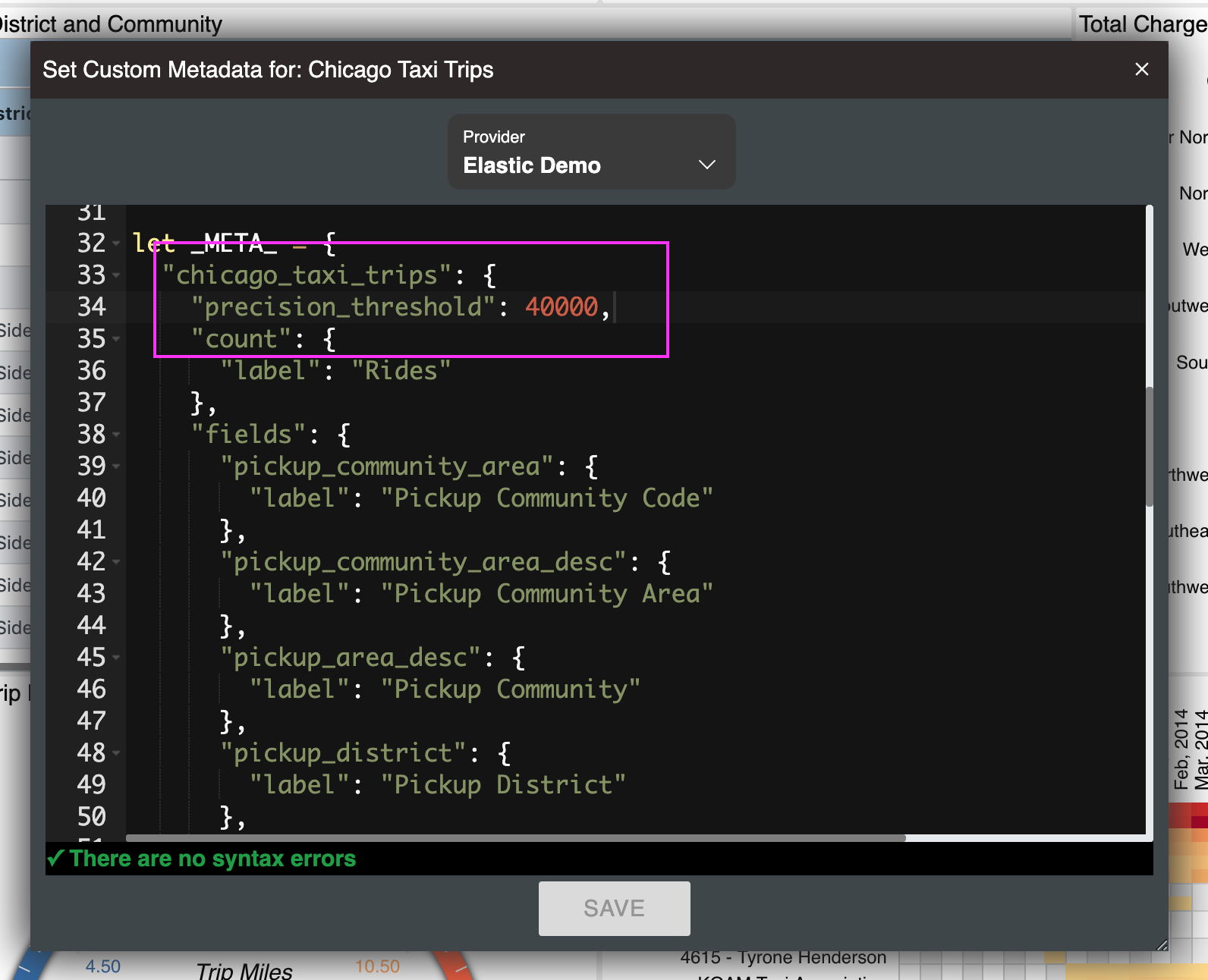
Thanks @eduardo, this actually helped. Had no idea about that feature of Elasticsearch. 